

Tóm Tắt
Trí tuệ nhân tạo (AI) đang trải qua một bước ngoặt quan trọng. Sau nhiều năm thống trị bởi các Mô Hình Ngôn Ngữ Lớn (Large Language Models – LLM) như ChatGPT, Claude, hay Gemini, nhiều nhà nghiên cứu hàng đầu thế giới đang đặt câu hỏi: liệu ngôn ngữ có thực sự là con đường dẫn đến trí thông minh tổng quát (AGI)? Câu trả lời ngày càng nghiêng về phía “không” – và hướng đi mới đang được hàng tỷ đô la đầu tư hướng đến chính là mô hình thế giới (world models): các hệ thống AI có khả năng mô phỏng, hiểu và dự đoán thế giới vật lý thực sự xung quanh chúng ta.
1. Bối Cảnh: Kỷ Nguyên Bùng Nổ Đầu Tư Vào AI
Để hiểu tại sao “world models” đang thu hút sự chú ý lớn như vậy, cần nhìn vào bức tranh đầu tư AI toàn cầu. Theo dữ liệu từ công ty phân tích Quid, năm 2025 thiết lập kỷ lục mới với hơn 581 tỷ USD đầu tư vào AI – gấp đôi con số 253 tỷ USD của năm 2024. Hoa Kỳ dẫn đầu với hơn 344 tỷ USD, chiếm gần 60% tổng đầu tư toàn cầu.
Tuy nhiên, đằng sau con số gây nhiều ấn tượng đó là một nhận thức ngày càng rõ ràng trong giới nghiên cứu: các mô hình AI hiện tại, dù mạnh mẽ đến đâu, vẫn đang thiếu một thứ gì đó rất cơ bản, đó là: khả năng nhận hiểu thế giới thực.
2. Giới Hạn Của Các Mô Hình AI Hiện Tại (LLM)
2.1 AI Biết Nói Nhưng Không Nhìn Thấy
Hãy nghĩ đến một đứa trẻ một tuổi chơi trò ú tim. Khi người lớn che mặt rồi bất ngờ hiện ra, đứa trẻ không chỉ giật mình – nó đang học rằng thứ gì đó vẫn tồn tại dù không nhìn thấy được. Đó là nền tảng của nhận thức vật lý: sự vật tiếp tục tồn tại và vận động ngay cả khi chúng ta không quan sát chúng.
Các hệ thống AI hiện nay, dù có khả năng trò chuyện và nhận dạng mẫu đáng kinh ngạc, không thể làm điều này một cách đáng tin cậy. Chúng có thể mô tả những gì đang hiện diện trước mắt, nhưng lại gặp khó khăn với các khái niệm như vật thể bị che khuất là gì, hoặc điều gì sẽ xảy ra tiếp theo trong một chuỗi hành động vật lý.
2.2 LLM: Thao Túng Ngôn Ngữ, Không Phải Hiểu Thực Tại
Yann LeCun, người được mệnh danh là “cha đỡ đầu của AI”, đã phát biểu thẳng thắn trong một bài giảng gần đây:
“Chúng ta có những hệ thống có thể thao túng ngôn ngữ, và chúng đánh lừa chúng ta khiến chúng ta nghĩ rằng chúng thông minh vì chúng thao túng ngôn ngữ. Nhưng thực ra, chúng hoàn toàn bất lực khi đối mặt với thế giới vật lý.”
Đây là vấn đề cốt lõi của LLM: chúng được huấn luyện trên hàng tỷ từ ngữ lấy từ internet, nhưng từ ngữ chỉ là biểu tượng của thực tại, không phải bản thân thực tại. Một mô hình ngôn ngữ có thể giải thích hoàn hảo về trọng lực, nhưng không “biết” rằng một quả bóng sẽ rơi xuống nếu không có tay đỡ.
2.3 Những Giới Hạn Cụ Thể
Các giới hạn của LLM thể hiện rõ nhất trong ba lĩnh vực quan trọng:
Robotics và tự động hóa vật lý: Một robot lau nhà cần hiểu rằng khi nó đẩy một chiếc ghế, chiếc ghế sẽ di chuyển theo một hướng nhất định và có thể đổ xuống. LLM không cung cấp được loại hiểu biết nhân quả này.
Xe tự lái: Để an toàn, xe tự lái cần dự đoán: “Nếu đứa trẻ kia tiếp tục chạy theo hướng đó, 2 giây nữa nó sẽ bước ra đường.” Đây là bài toán dự đoán tương lai vật lý mà LLM không được thiết kế để giải quyết.
Y tế và phẫu thuật: Mô phỏng quy trình phẫu thuật đòi hỏi hiểu biết về cấu trúc giải phẫu ba chiều (3D), tính chất vật liệu của mô, và phản ứng của cơ thể với từng tác động – những thứ không thể học từ văn bản đơn thuần.
3. World Models Là Gì?
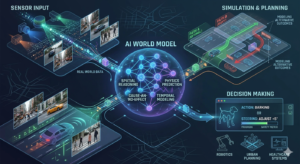
3.1 Định Nghĩa
Mô Hình Thế Giới (world models) là các hệ thống AI được thiết kế không chỉ để nhận dạng các mẫu trong văn bản hay hình ảnh, mà còn để mô phỏng cách thế giới vật lý hoạt động. Bằng cách huấn luyện trên hàng triệu giờ video, các mô hình này xây dựng một phiên bản hình ảnh chính xác về cách thế giới vận hành – bao gồm vật lý, quan hệ nhân quả, và diễn tiến theo thời gian.
Nói một cách đơn giản: nếu LLM học từ những gì người ta nói về thế giới, thì world models học từ những gì thực sự xảy ra trong thế giới.
3.2 Nguồn Gốc Học Thuật
Phần lớn các nỗ lực xây dựng world models ngày nay có thể truy nguyên về một bài báo năm 2018 của David Ha và Jürgen Schmidhuber. Bài báo đề xuất một cách tiếp cận khác biệt: trước khi AI có thể hành động thông minh, nó cần học cách thế giới hoạt động thông qua một phiên bản mô phỏng của môi trường đó.
David Ha, hiện là đồng sáng lập công ty AI Nhật Bản Sakana, mô tả cơ chế này là cho phép AI luyện tập bên trong các phiên bản mô phỏng thực tại – cái mà ông gọi là “những giấc mơ ảo giác” – nơi một tác nhân có thể thực hành và lập kế hoạch trước khi hành động trong thế giới thực.
3.3 Phép Ẩn Dụ Từ Điện Ảnh
Ming-Yu Liu, Phó Chủ tịch tại Cosmos Lab của Nvidia, đã đưa ra một phép so sánh sinh động: hãy nghĩ đến bộ phim The Matrix, trong đó nhân vật chính học võ thuật bên trong một thế giới mô phỏng. World models chính là “cơ sở huấn luyện tạo sinh” như vậy – “có phản hồi và hướng dẫn để AI liên tục nâng cao kỹ năng của mình.”
4. Những Tên Tuổi Lớn Đang Đầu Tư Hàng Tỷ Đô
4.1 Fei-Fei Li và World Labs
Fei-Fei Li, giáo sư Đại học Stanford và được mệnh danh là “mẹ đỡ đầu của AI”, đã sáng lập World Labs vào năm 2024. Mục tiêu của startup này là mang lại cho AI nhận thức phong phú hơn về không gian 3D và về cách các vật thể tồn tại và tương tác trong đó. Tính đến đầu năm 2026, World Labs đã huy động được khoảng 1 tỷ USD vốn đầu tư.
4.2 Yann LeCun và AMI Labs
Sau 12 năm gắn bó với Meta (7 năm với tư cách Trưởng nhà khoa học AI), Yann LeCun đã rời công ty vào tháng 12/2025 để thành lập Advanced Machine Intelligence (AMI) Labs. Đây là nỗ lực tham vọng nhất từ trước đến nay nhằm thương mại hóa nghiên cứu về world models.
AMI Labs bước vào vòng gọi vốn với mức định giá 3 tỷ euro trước khi ra mắt bất kỳ sản phẩm nào – một trong những đợt gọi vốn trước ra mắt lớn nhất trong lịch sử AI. Công ty đặt mục tiêu tạo ra các hệ thống AI có thể: Hiểu vật lý và tính nhân quả; duy trì bộ nhớ liên tục (persistent memory); lập kế hoạch cho các hành động phức tạp – thay vì chỉ đơn giản dự đoán chuỗi văn bản.
4.3 Google và Project Genie
Google gần đây đã tiết lộ bản xem trước nghiên cứu có tên Project Genie – có khả năng tạo ra các môi trường tương tác, siêu thực từ các gợi ý đơn giản, sau đó dự đoán cách những thế giới đó phát triển và phản hồi với hành động của người dùng.
4.4 Alibaba và Shengshu/Vidu
Từ phía Trung Quốc, Alibaba Cloud dẫn đầu một khoản đầu tư trị giá 2 tỷ nhân dân tệ (khoảng 290 triệu USD) vào ShengShu – startup đứng sau công cụ tạo video AI Vidu. Khoản đầu tư này nhằm vượt ra ngoài AI dựa trên văn bản để hướng đến công nghệ mô phỏng thực tế, một hướng đi cần thiết để thúc đẩy robotics.
5. Ứng Dụng Thực Tiễn
World models không chỉ là lý thuyết nghiên cứu – chúng hướng đến những ứng dụng cụ thể và có tác động lớn:
Xe tự hành: Dự đoán hành vi của người đi bộ, xe đạp và các phương tiện khác trong tình huống phức tạp, bao gồm các kịch bản chưa từng gặp trong dữ liệu huấn luyện.
Robotics gia đình và công nghiệp: Dạy robot các kỹ năng mới chỉ từ một vài ví dụ – kể cả những kỹ năng mà robot chưa bao giờ thực hiện trước đó – rồi thực hiện chúng một cách nhất quán.
Phẫu thuật và y tế: Mô phỏng quy trình phẫu thuật trước khi thực hiện, dự đoán phản ứng của cơ thể.
Game và giải trí tương tác: Tạo ra các thế giới game phản ứng và thay đổi theo thời gian thực dựa trên hành động của người chơi.
Giáo dục và đào tạo: Môi trường mô phỏng để luyện tập các kỹ năng vật lý trong không gian ảo an toàn.
6. Thách Thức Kỹ Thuật và Kinh Tế
6.1 Chi Phí Tính Toán Khổng Lồ
Đào tạo các hệ thống có thể mô phỏng thế giới thực đòi hỏi sức mạnh tính toán lớn hơn nhiều so với các mô hình ngôn ngữ hiện tại, vì chúng cần xử lý không chỉ từ ngữ mà còn cả video độ phân giải cao.
Odyssey cho biết cần một chip H200 của Nvidia – mỗi chip có giá lên đến 40.000 USD – cho mỗi người dùng truy cập mô hình Odyssey 2 thông qua API. Đây là mức chi phí cực kỳ cao so với việc phục vụ người dùng LLM thông thường.
6.2 Dữ Liệu: Bài Toán Nan Giải
Không giống như LLM được huấn luyện trên dữ liệu văn bản khổng lồ có thể thu thập dễ dàng từ internet, world models phụ thuộc nặng nề vào video – thứ phức tạp hơn nhiều và khó thu thập, gán nhãn, và huấn luyện ở quy mô lớn.
Đây là lý do các công ty như Niantic Spatial có lợi thế đặc biệt: hàng triệu người chơi Pokémon Go đã không chủ ý đóng góp 30 tỷ hình ảnh và bản quét 3D của thế giới thực qua nhiều năm.
6.3 Vấn Đề Tốc Độ
Không chỉ cần tạo ra mô phỏng chính xác – mô phỏng đó phải xảy ra đủ nhanh để có ích trong thực tế. Đây là “điểm mở khóa then chốt” mà Decart đang cố gắng giải quyết khi họ tạo ra video nhanh đến mức khớp với hành động của người dùng từng khung hình.
7. Tranh Luận Trong Giới Nghiên Cứu
Không phải tất cả mọi người đều đồng ý rằng World Models là bước đột phá tiếp theo. Có hai trường phái chính đang tranh luận:
Trường phái “Scale is all you need”: Nhiều nhà nghiên cứu tin rằng các LLM, nếu được mở rộng đủ lớn với đủ dữ liệu đa phương thức (bao gồm cả video), cuối cùng sẽ tự phát triển khả năng hiểu thế giới vật lý.
Trường phái “World Models First” (LeCun, Li và những người khác): Họ lập luận rằng kiến trúc LLM về cơ bản bị giới hạn bởi bản chất dự đoán token của nó – và sẽ không bao giờ đạt đến trí thông minh tổng quát nếu không có một cơ chế lập mô hình thế giới riêng biệt.
Như blog Introl ghi nhận, paradigm world models đã bùng nổ vào dòng chính của phát triển AI vào cuối năm 2025 và đầu năm 2026, nhưng cuộc tranh luận cơ bản vẫn chưa được giải quyết.
8. Tín Hiệu Từ Thị Trường: “Khoảnh Khắc ChatGPT” Đang Đến Gần?
Bất chấp những tranh luận học thuật, tín hiệu từ thị trường rất rõ ràng. Ming-Yu Liu của Nvidia nhận định rằng một “khoảnh khắc ChatGPT” cho AI World Models đang gần kề – một bước nhảy vọt về năng lực có thể thay đổi toàn bộ cách mọi người nghĩ về robotics và tự động hóa vật lý.
Mục tiêu cá nhân của ông là dạy robot những kỹ năng mới chỉ từ một vài ví dụ – kể cả những ví dụ mà robot chưa từng gặp – rồi thực hiện chúng một cách nhất quán. “Tôi thực sự tin rằng mọi người đang dần tìm ra công thức đúng đắn,” ông nói.

9. Kết Luận
AI World Models đại diện cho một sự thay đổi nhận thức sâu sắc trong cách cộng đồng AI tư duy về trí thông minh. Câu hỏi không còn là “làm thế nào để AI nói chuyện giỏi hơn?” mà là “làm thế nào để AI hiểu và tương tác với thế giới thực?”
Các mô hình ngôn ngữ lớn đã mang lại những bước tiến phi thường trong thập kỷ qua – nhưng chúng được xây dựng trên nền tảng ngôn ngữ, không phải vật lý. Thế giới thực chuyển động, thay đổi, và phản ứng theo những cách mà văn bản không thể nắm bắt đầy đủ.
World models là nỗ lực để lấp đầy khoảng cách đó – và với hàng tỷ đô la đang đổ vào, cùng với sự tham gia của những tên tuổi hàng đầu như Yann LeCun, Fei-Fei Li, Google, Nvidia và Alibaba, đây không còn là một hướng nghiên cứu ngoài lề. World Models đang trở thành mặt trận tiếp theo của AI.
Phụ Lục: Các Công Ty và Nhân Vật Chính
| Tên | Vai trò | Hoạt động chính |
| Fei-Fei Li | “Mẹ đỡ đầu của AI”, GS Stanford | Sáng lập World Labs (2024), ~1 tỷ USD vốn |
| Yann LeCun | “Cha đỡ đầu của AI” | Sáng lập AMI Labs (2026), 3 tỷ euro định giá |
| Google DeepMind | Gã khổng lồ công nghệ | Project Genie – môi trường tương tác thực tế |
| Nvidia Cosmos Lab | Phần cứng AI | Cơ sở hạ tầng và nghiên cứu AI vật lý |
| Alibaba Cloud | Tập đoàn công nghệ TQ | Đầu tư 290M USD vào Shengshu/Vidu |
| Niantic Spatial | Startup (San Francisco) | Mô hình địa không gian lớn, 30 tỷ hình ảnh 3D |
| Decart | Startup (Tel Aviv) | World models thời gian thực |
| Odyssey | Startup (Palo Alto) | Dự đoán tương lai vật lý từ video |
| Sakana AI | Công ty R&D (Nhật Bản) | Nghiên cứu nền tảng, đồng sáng lập David Ha |



